A New Frontier in Artificial Intelligence: Multimodal Learning

Learning modalities are sensory channels through which information can be given, received, or stored. These modalities include visuals, text, speech, and kinetics. Multimodal learning is a new paradigm in Artificial intelligence (AI) where higher performances by combining multiple algorithms with various modalities (visuals, text, speech). As opposed to unimodal learning, the standard AI functionality, multimodal learning offers more.
Unimodal Learning Vs. Multimodal learning in AI:
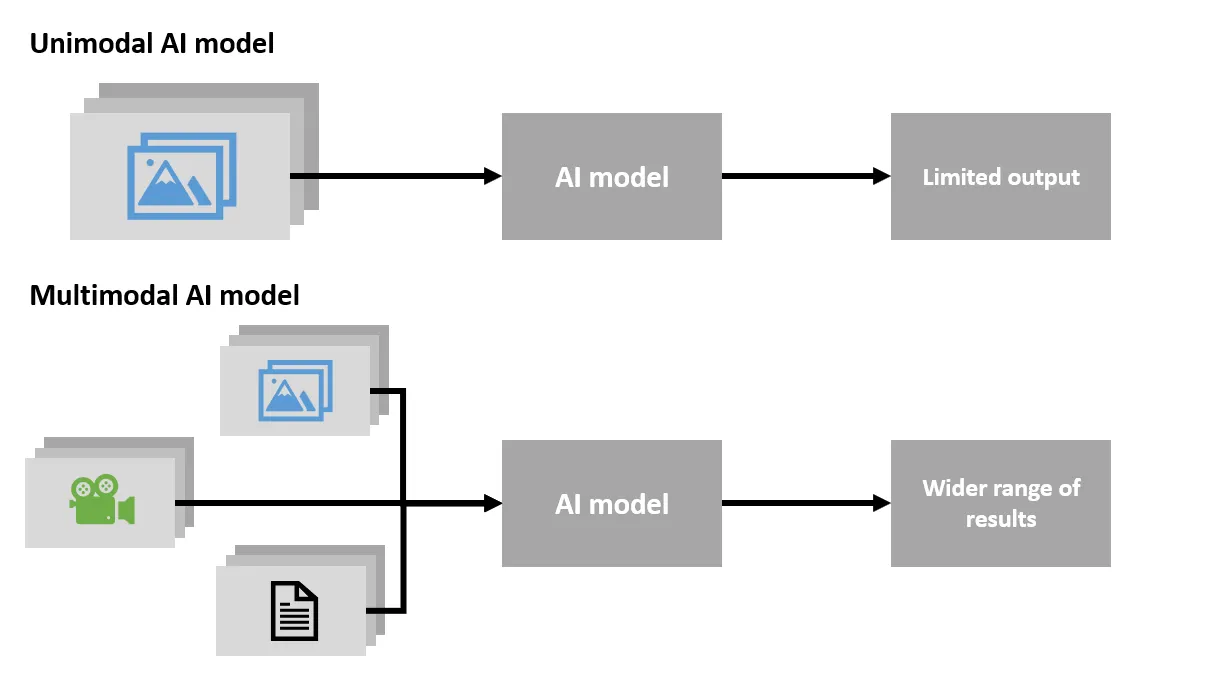
AI systems are usually unimodal; they take one kind of input (language, text, image) and try to do tasks using that input. This means that the systems are fed a single sample of data from which they can identify the corresponding words or images. Although working with a single piece of data seems easier, this limits results and the deductions that can be made for that single sample.
The human mind can process different information from all the various sense organs. It was on this principle that multimodal learning in AI was based. Multimodal learning takes other inputs (image, text, sound) to process and gives various deductions and results. For instance, the multimodal AI does not just focus on a sample image of a leopard presented; it also focuses on how the leopard sounds, how it is written, where it can be found, etc. this means at anytime a leopard is mentioned, all that can be experienced is not just an image but all the combined modalities for a leopard.
Some of the benefits of multimodal learning include improved capabilities and improved accuracy.
With multimodal learning, the AI learns from one modality and finds other representations that will benefit another modality.
Applications of Multimodal learning:
1) Text-to-Image generation:
Text-to-image generation is creating images related to given texts. These images are realistic and are semantically related to the given text input. An example can be seen using web searches.
2)Visual Question Answering:
In VQA, an algorithm needs to answer text-based questions about images. This is possible because of multimodal learning.
3)Video Language Modelling:
With multimodal AI, video tasks are processed quickly. Sampled frames are operated on and optimized end-to-end to solve the video language tasks.
Other real-life applications include automated translators, Google’s video-to-text research that can predict the subsequent dialogues, etc.
Conclusion
Multimodal learning has been able to overcome challenges being faced presently in AI. It presents more accurate and precise answers owing to the combination of the different modalities in processing the samples. Furthermore, with multimodal AI, experiences are more human and more interactive. This attempts to make technological experiences as human as possible, appealing to the different senses.
